One of the Hot domains in the current IT market is DevOps, one common question I get quite often is, “How to become a DevOps engineer?“

DevOps is not about any tools or technologies. It is a philosophy for making different IT teams (Developers, Platforms teams, QA, Performance, etc) work together to deliver better and fast results through continuous feedback.
How To Become a devops Engineer?
Becoming a DevOps engineer involves learning a combination of skills in software development and systems administration.
To become a DevOps engineer, the first and foremost thing is to understand the DevOps culture. It is all about different teams working together towards a common goal. In other words, there should not be any blaming culture between different IT teams.
Here are some steps you can take to start your journey toward becoming a DevOps engineer:
- Learn Linux
- Learn about version control
- Learn about system administration
- Learn about Infrastructure Components
- Learn about Jenkins or Gitops
- Learn Cloud Computing & Virtualization
- Learn Infrastructure Automation in devops
- Learn Container Orchestration and Kubernetes
- Logging & Monitoring & Observability
- Learn basic Coding(Preferable Python) & Scripting(Bash)
- CI/CD Process in devops
Learn Linux

Learning Linux is a valuable skill for anyone interested in a career in tech, including as a DevOps engineer. Here are some steps you can take to start learning Linux:
- Install a Linux distribution: You can install a Linux distribution, such as Ubuntu, on your computer or create a virtual machine to run Linux. This will allow you to practice using the command line and perform tasks like installing software and configuring the system.
- Learn the command line: A command line is a powerful tool for interacting with a Linux system. Start by learning the basic commands and how to navigate the file system. You can also learn how to use shells like bash and zsh, and how to use tools like grep and sed to process text.
- Learn Linux concepts: There are a number of concepts specific to Linux that you should learn, such as the structure of the file system, users and groups, and system logs. You can find resources online or in books to learn about these topics.
- Practice with exercises: You can find exercises and practice problems online to help you apply what you’ve learned and gain hands-on experience with Linux.
- Join a community: There are many online communities where you can ask questions and get help with learning Linux. You can also consider joining a local Linux user group or participating in online forums and discussion groups.
Learn about version control

Source control, also known as version control, is a system that tracks changes to files over time and allows multiple developers to collaborate on a project. There are several tools available for source control, including Git, Mercurial, and Subversion. Here are some steps you can follow to learn how to use source control:
- Choose a source control tool: Git is a popular choice for source control, and it is widely used in the software industry. You can download Git for free from the official website (https://git-scm.com/).
- Set up a repository: A repository is a central location where you can store your code and track changes. You can create a repository on your local machine or on a hosting service such as GitHub, GitLab, or Bitbucket.
- Learn the basic commands: There are several basic commands that you will use frequently when working with source control. These include
git add,git commit, andgit push. You can find a complete list of Git commands at https://git-scm.com/docs. - Practice using source control: The best way to learn how to use source control is to practice using it on a real project. You can create a new project and start adding and committing your code to the repository.
- Learn about branching and merging: Branching allows you to create separate versions of your code that you can work on concurrently. You can then merge your changes back into the main branch when you are ready to incorporate them into the main project.
- Collaborate with others: Source control is designed to support collaboration, so you can work with other developers on the same project. You can collaborate by pushing and pulling changes to and from the repository and by using features such as pull requests to review and merge code changes.
Learn about system administration
System administration refers to the tasks and responsibilities involved in managing and maintaining the operations of a computer system or network. This can include tasks such as installing and configuring software, setting up user accounts and permissions, backing up data, monitoring system performance, and troubleshooting problems.
Some of the specific responsibilities of a system administrator may include:
- Installing and configuring operating systems, applications, and network devices
- Setting up and managing user accounts, permissions, and security settings
- Ensuring that the system is secure and compliant with company policies and industry regulations
- Monitoring system performance and troubleshooting issues as they arise
- Implementing and maintaining backup and disaster recovery plans
- Managing system updates and patches
- Creating and maintaining documentation for the system and its processes
To become a system administrator, you typically need to have a strong foundation in computer science, as well as practical experience with different operating systems and networking technologies.
Learn about Infrastructure Components
Infrastructure components are the building blocks of an IT infrastructure. They are the physical and logical components that support the operation of an organization’s IT systems and services. Some examples of infrastructure components include:
- Servers: A server is a computer that provides resources and services to other computers or devices on a network. Examples of servers include file servers, which store and manage files for users on the network, and web servers, which host websites and provide access to them over the internet.
- Networking equipment: Networking equipment is used to connect devices on a network and facilitate communication between them. Examples of networking equipment include routers, switches, and hubs.
- Storage systems: Storage systems are used to store and manage data for an organization. Examples of storage systems include storage area networks (SANs), network-attached storage (NAS), and cloud storage.
- Data centers: A data center is a physical facility that houses an organization’s IT infrastructure, including servers, networking equipment, and storage systems. Data centers are designed to provide a secure and reliable environment for storing and managing an organization’s data and IT systems.
- Virtualization: Virtualization is the process of creating a virtual version of a physical resource, such as a server or storage system. Virtualization allows an organization to make more efficient use of its IT resources by allowing multiple virtual resources to be created and managed on a single physical resource.
- Cloud computing: Cloud computing is a model for delivering IT services over the internet. It allows an organization to use remote servers and other resources to store, process, and manage data and applications, rather than relying on local servers and hardware.
Learn about Jenkins or Gitops
Jenkins is an open-source automation server that helps automate parts of the software development process. It helps to automate building, testing and deploying software applications. Jenkins can be used to automate tasks such as:
- Building and testing software projects
- Running tests
- Deploying software
- Automating the release process
GitOps is a method for managing infrastructure and applications using Git as a single source of truth. It involves using Git to store declarative configuration files that specify the desired state of an application or infrastructure. Changes to these configuration files are made using pull requests, just like with any other code changes. An automated system is then used to apply these changes to the live environment.
GitOps aims to provide a more reliable and efficient way of managing infrastructure and applications by using Git as a central source of truth and automating the process of deploying changes. It can be used in combination with tools like Jenkins to automate the deployment process.
Learn Cloud Computing & Virtualization
Cloud computing is a model for delivering computing resources (such as networking, storage, and processing power) over the internet. It allows users to access these resources on demand, without the need to purchase and maintain physical infrastructure.
Cloud computing providers offer a range of services, including Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). These services can be accessed through various delivery models, including public clouds, private clouds, and hybrid clouds.
Virtualization is a technology that allows a single physical machine to be divided into multiple virtual machines, each running its own operating system. Virtualization allows multiple virtual machines to share the resources of a single physical machine, and enables the creation of virtual infrastructure.
Virtualization is often used in conjunction with cloud computing to enable the creation of virtual resources that can be accessed over the internet. For example, a cloud provider might use virtualization to create a pool of virtual machines that can be used to host applications and services for their customers.
Most of the public cloud market share is currently owned by AWS. Here is the latest report from Statista.
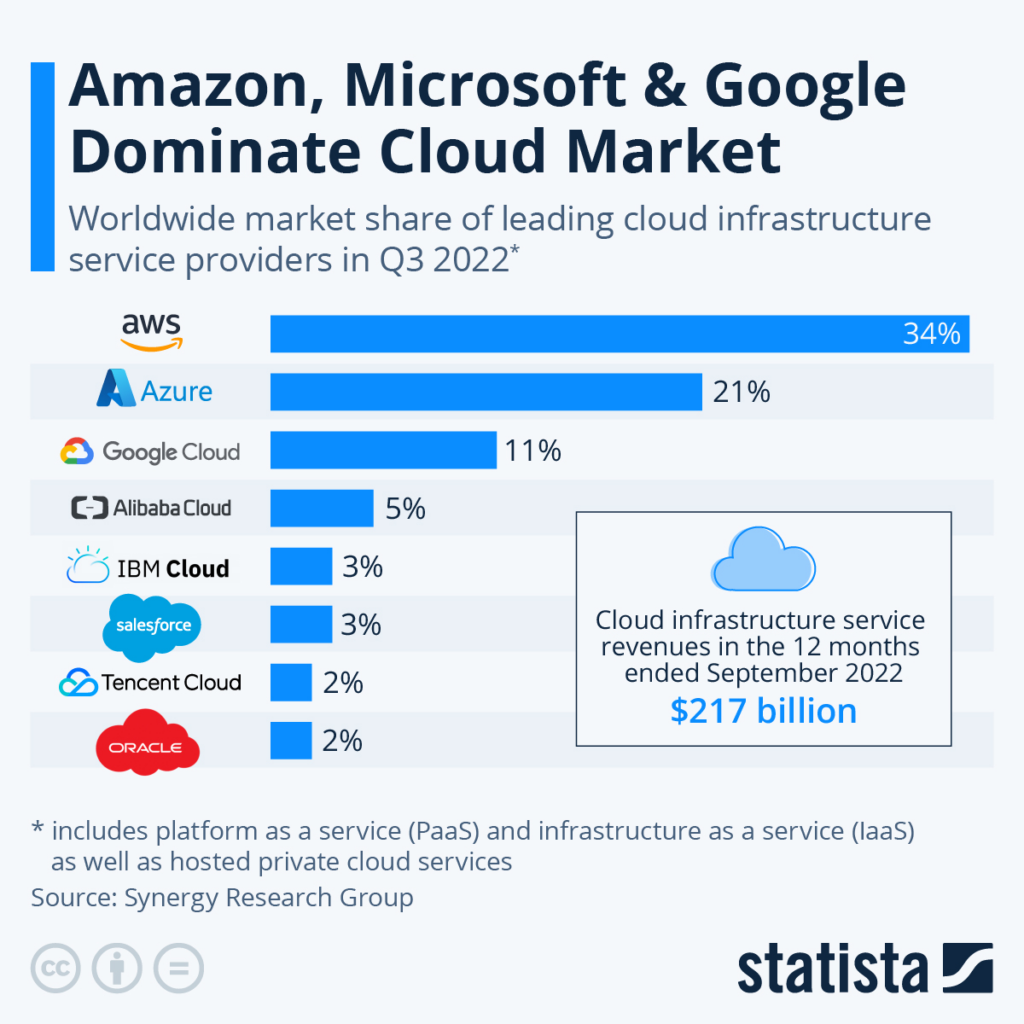
Learn Infrastructure Automation in devops
Automation is a key part of the DevOps philosophy.
Infrastructure automation refers to the use of tools and processes to automate the provisioning and management of infrastructure resources, such as servers, storage, and networking. The goal of infrastructure automation is to make it easier and faster to provision, configure, and manage infrastructure resources, while also reducing the risk of errors and increasing the reliability of the infrastructure.
There are several tools and approaches that can be used for infrastructure automation, including:
- Infrastructure as Code (IaC): This approach involves using configuration files written in a high-level language to define the desired state of the infrastructure. These configuration files can be stored in a version control system and managed just like any other code. Tools like Ansible, Terraform, and CloudFormation can be used to automate the provisioning and management of infrastructure resources based on these configuration files.
- Configuration Management Tools: These tools, such as Chef, Puppet, and SaltStack, can be used to automate the configuration and management of infrastructure resources. They use a declarative approach, in which the desired state of the infrastructure is defined and the tool takes care of ensuring that the infrastructure is in the desired state.
- Containerization: Containerization technologies, such as Docker, allow applications to be packaged in a lightweight, portable container that can be easily deployed and run on any infrastructure. This makes it easier to automate the deployment and management of applications, as the same container can be used on any infrastructure without the need to worry about differences in operating systems or environments.
Overall, infrastructure automation can help to increase the efficiency and reliability of infrastructure, as well as improve the speed at which changes can be made.
Learn Container Orchestration and Kubernetes
Container orchestration refers to the process of automating the deployment, scaling, and management of containerized applications. Containers are a lightweight and portable way to package applications and their dependencies, and they allow applications to be easily deployed and run on any infrastructure. However, managing and scaling a large number of containerized applications can be complex, and this is where container orchestration tools come in.
Kubernetes is an open-source container orchestration platform that was originally developed by Google. It allows users to automate the deployment, scaling, and management of containerized applications. Kubernetes is designed to be highly scalable, and it can be used to manage hundreds or thousands of containers across multiple hosts.
In Kubernetes, containerized applications are organized into logical units called pods. Pods can contain one or more containers, and they are the basic unit of deployment in Kubernetes. Kubernetes provides a number of features to help automate the deployment and management of pods, including:
- Automated rollout and rollback of changes
- Self-healing capabilities (e.g., automatically restarting containers that fail)
- Automatic binpacking (i.e., placing pods on the most suitable nodes based on resource availability)
- Service discovery and load balancing
Overall, Kubernetes is a powerful tool for automating the deployment, scaling, and management of containerized applications at scale.
Logging & Monitoring & Observability

Logging, monitoring, and observability are important practices in the field of DevOps. They involve the collection and analysis of data about the performance and behavior of systems and applications, with the goal of detecting and addressing issues, improving reliability and performance, and providing visibility into the operation of the systems.
Logging refers to the process of collecting and storing data about the operation of a system or application. This data is typically stored in log files, and it can include information about events, errors, and other important activities that occur within the system. Logs can be used to diagnose issues, track changes, and provide a record of activity for compliance and auditing purposes.
Monitoring refers to the continuous monitoring of systems and applications to detect and alert on potential issues. This can involve collecting and analyzing data from various sources, such as log files, performance metrics, and application-specific data. Monitoring tools can be used to set up alerts and notifications that are triggered when certain thresholds or conditions are met.
Observability refers to the practice of designing systems in such a way that they can be easily monitored and understood. This involves collecting and exposing data about the operation of the system in a structured and consistent way so that it can be easily analyzed and understood. Observability practices, such as structured logging and exposing metrics and other system data, can help to improve the reliability and performance of systems by making it easier to detect and diagnose issues.
Learn basic Coding(Preferable Python) & Scripting(Bash)
Python is a popular language for implementing DevOps practices.
Here are some steps you can take to start learning Python for DevOps:
- Learn the basics of Python: If you are new to Python, it is important to first learn the basics of the language. This might include learning about variables, data types, operators, and control structures such as loops and conditional statements. There are many online tutorials and resources available that can help you get started.
- Learn about Python libraries and modules: Python has a large standard library and a vast ecosystem of third-party libraries and modules that can be used to extend its capabilities. As you progress in your learning, you may want to explore some of these libraries and learn how to use them to solve specific problems.
CI/CD Process in devops
CI/CD (Continuous Integration/Continuous Deployment) is a software development practice that involves automatically building, testing, and deploying code changes. The goal of CI/CD is to improve the speed and reliability of software delivery by automating as much of the process as possible.
Here is a general outline of the CI/CD process:
- Development: Developers write code and commit their changes to a version control system such as Git.
- Continuous integration: When a code change is made and committed, it is automatically built and tested by a CI/CD tool such as Jenkins or Travis CI. If the build and tests pass, the change is automatically merged into the main branch of the codebase.
- Continuous delivery: Once the code change has been integrated and tested, it can be automatically deployed to a staging or testing environment for further testing and validation.
- Continuous deployment: If the code change passes testing in the staging environment, it can be automatically deployed to production, making it available to end users.
Overall, the CI/CD process aims to improve the speed and reliability of software delivery by automating as much of the process as possible and catching errors early in the development cycle.